7.4 Identifying Email Text Content Using TextCensor Scripts
TextCensor scripts check for the presence of particular lexical (text) content in an email message. MailMarshal can check one or more parts of a message, including the message headers, message body, and any attachments that can be lexically scanned.
Apply TextCensor scripts to email messages by using Content Analysis Policy rules.
A script can include many conditions. Each condition is based on words or phrases combined using logical and positional operators. The script matches, or triggers, if the weighted result of all conditions reaches the target value you set.
|

|
Note: For MailMarshal to detect and block explicit language (such as profanity and pornographic language), objects such as the Email Policy rules and the TextCensor scripts need to contain that explicit language. Anyone who has permission to use the MailMarshal Management Console or Marshal Reporting Console may be exposed to this explicit language. As this language may be objectionable, please follow your company's policy with respect to exposure to content of this type.
|
7.4.1 TextCensor Elements
TextCensor scripts contain one or more expressions, each consisting of a word or phrase.
7.4.1.1 Wildcards
You can use two wildcard characters, anywhere in a word or phrase.
•* matches zero or more letter or digit characters or ideographs.
•? matches one letter, digit, or ideograph.
Wildcards match only letters and digits, and apostrophes or hyphens that are treated as part of words (see “Word Breaks”). Wildcards do not match other symbol characters.
|
|
Notes:
•You cannot use pure wildcard patterns comprised entirely of a mixture of [DIGIT], [LETTER], *, or ?
•Make patterns as specific as possible. Patterns that produce a very large number of matches will take a long time to evaluate and consume unacceptable amounts of system resource. For example, do not use the patterns *e* or a* when evaluating English-language documents.
|
If you want to set the order of evaluation of a complex expression that uses more than one operator, use parentheses ( ).
Each TextCensor expression can include logical and positional operators. The operators must be entered in UPPERCASE.
7.4.1.2 Positional Operators
TextCensor works with the positions of words or phrases within a file. For example, in the sentence “The quick brown fox jumps over the lazy dog” the word “quick” starts and ends at position 2, and the phrase “jumps over” starts at position 5 and ends at position 6.
A positional operator works with expressions that evaluate to sets of positions. It takes two sets of positions as parameters, and returns a new set of positions.
|

|
Tip: In a simple TextCensor expression, you can think of the expression result as “true” or “matched” if the word or phrase is found in any position in the text. When the word or phrase is found in more than one position, this counts as more than one match of the expression.
When you combine positional operators to make a complex expression, note the explanations of the sets returned by each operator (see below). Test your script before applying it in production.
|
You can specify a distance for many positional operators. The default distance (if you do not specify a value) is 4.
Table 14: TextCensor Positional Operators
|
Operator and Syntax
|
Matching Results
|
|
FOLLOWEDBY
A FOLLOWEDBY[=distance] B
|
The start of B occurs within distance words from the end of A. Returns a set of positions spanning from the start of A to the end of B.
dog FOLLOWEDBY hous* matches Dog in the house
|
|
NOT FOLLOWEDBY
A NOT FOLLOWEDBY[=distance] B
|
The start of B does not occur within distance words from the end of A. Returns a set containing the positions in A that are not followed by B.
dog NOT FOLLOWEDBY=1 hous* matches Dog in the house
|
|
PRECEDEDBY
A PRECEDEDBY[=distance] B
|
The end of B occurs within distance words from the start of A. Returns a set of positions spanning from the start of B to the end of A.
dog PRECEDEDBY cat matches Cat chasing dog
|
|
NOT PRECEDEDBY
A NOT PRECEDEDBY[=distance] B
|
The end of B does not occur within distance words from the start of A. Returns a set containing the positions in A that are not preceded by B.
dog NOT PRECEDEDBY=2 cat matches Cat was not chasing dog
|
|
NEAR
A NEAR[=distance] B
|
If A occurs within distance words before B the resulting position spans from the start of A to the end of B. If B occurs within distance words before A the resulting position spans from the start of B to the end of A.
dog NEAR cat matches Cat chasing dog and also matches Dog chasing cat
|
|
NOT NEAR
A NOT NEAR[=distance] B
|
Returns the positions of all instances of A where B is not found within distance words from A
dog NOT NEAR=2 cat matches Cat was not chasing dog and also matches Dog was not chasing cat
|
|
OR
A OR B
|
This form of the OR operator is applied when both A and B are sets of positions, even if one or both are empty sets. It returns the union of position sets A and B.
For the sentence “A rose is a rose”, the expression (rose OR is) returns the position set 2,3,5.
|
7.4.1.3 Logical (Boolean) and Special Operators
A logical operator takes Boolean (true/false) values as input, and returns a Boolean result. These results cannot be used as parameters of a positional operator.
When one of the parameters to a logical operator is an expression that returns a position set, the parameter is treated as a logical value. A set with at least one position match is treated as true. A set that has no matches is treated as false.
TextCensor also supports the special operator INSTANCES.
Table 15: TextCensor Logical and Special Operators
|
Operator and Syntax
|
Matching Results
|
|
OR
A OR B
|
Returns true if A or B (or both) is true. This form of the OR operator is applied when either A or B (or both) are logical expressions. If both A and B are position sets then the positional OR operator is used instead.
|
|
AND
A AND B
|
Returns true if both A and B are true.
|
|
NOT
NOT A
|
Returns the opposite of A (true if A is false).
|
|
INSTANCES
A INSTANCES=count
|
A must be an expression that returns a position set. The result is true if A contains count or more word positions; otherwise the result is false.
|
7.4.1.4 Anchored Regular Expressions
TextCensor supports use of Regular Expressions through the ARX operator.
An anchored regular expression is a regular expression (regex) which must be preceded by a word on the left hand side of the ARX operator. Matching of the regex begins at the next character following the word. Regex patterns should always begin by matching one or more non-word characters. In most cases you can start the regex pattern with \W (to match whitespace).
|
|
Notes:
•ARX is based on Google RE2. The syntax is generally similar to the syntax used in MailMarshal Header Matching (see “Regular Expressions”).
•Distance parameters for ARX operators are specified in characters. The default is 100 characters.
•Regular expressions are case insensitive by default. You can force case sensitive matching with the operator ?-i
•ARX does not support lookahead or lookbehind.
•ARX does not support capture groups. Capture groups will be ignored or converted to non-capturing sequences.
•ARX does not support \Q...\E literal text.
•For further details of the ARX syntax, see the RE2 wiki.
|
Table 16: TextCensor Regular Expression Operators
|
Operator and Syntax
|
Matching Results
|
|
ARX
A ARX[=distance] /pattern/
|
Locates instances of A where it is followed by text matching the regex pattern within distance characters of the end of A. The entire pattern must occur within the specified distance. The resulting position list spans from the beginning of A to any content matched by the regex.
dog chasing ARX /\W(one|two|10) cat(s*)/
|
|
NOT ARX
A NOT ARX[=distance] /pattern/
|
Locates instances of A where text matching the regex pattern does not occur within distance characters of the end of A. When this expression matches, the resulting position list is the position list of A.
|
Multiple anchored regular expressions can be combined with other expressions and operators to create complex statements. For example,
((dog OR boy) FOLLOWEDBY=1 ((chasing OR leading) ARX /\W(one|two|10)/) NEAR big) FOLLOWEDBY (white ARX /\W(horse|cat)s*/)
matches the phrase: dog chasing one or more big white cats.
7.4.2 TextCensor Concepts
The following concepts clarify how TextCensor expressions are evaluated.
|
|
Note: This section does not apply to Regular Expression patterns.
|
7.4.2.1 Words
A word is made up of one or more letters and digits, and sometimes symbols.
•In alphabetic languages, a word is a group of letters or digits separated by other characters (such as punctuation, other symbols, and white space).
•In Chinese, or Japanese kanji, a word or “token” may be composed of one or more characters (ideographs).
7.4.2.2 Phrases
A phrase is made up of a series of words separated by word break characters.
7.4.2.3 Symbols and Punctuation
Symbols other than letters and digits are not treated as part of a word unless they appear in the specific statement being evaluated. A group of symbols is not treated as a word.
|
|
Tip:
•The text word$deed is matched as two words by the expression word FOLLOWEDBY deed, and also by the exact expression word$deed
•The text $word$ is matched by any of word, $word, word$, or $word$
•The text Save $$$ Now is matched by save FOLLOWEDBY=1 now
|
7.4.2.4 Word Breaks
The sets of characters that are treated as word and number break characters generally follow Unicode standards.
A word break character can also be matched exactly or by a wildcard.
|
|
Tip:
•Each of the following strings is treated as one word:
John’s
3.14159
1,234.56
3a
REV.B (the full stop between letters with no surrounding spaces is not a word break)
•The text half-baked is treated as two words and is matched by any of the following expressions:
half FOLLOWEDBY=1 baked
half-baked
half?baked
|
7.4.2.5 Accented Letters
TextCensor treats each accented character as a single letter. A letter with additional composed accent characters is normalized to a single character before the text is evaluated.
7.4.2.6 Escape Characters
Some characters have special meanings in TextCensor. These characters are parentheses, square braces, the asterisk, the equal sign, the double quote character, and the question mark. You can place a backslash character (‘\’) before any of these characters in order to use the character’s normal meaning. To use a normal backslash character, place two of them together (“\\”).
Within ARX expressions, the Regular Expression reserved characters apply (in particular the forward slash ‘/’) which marks the start and end of the regex pattern).
7.4.2.7 Case Sensitivity
TextCensor evaluation is NOT case sensitive by default. To perform a case sensitive match, quote the content using double quote characters. All special characters and escape characters retain their meaning within double quotes.
7.4.2.8 Classes
You can use TextCensor Classes to match specific types of characters inside a word, or special types of words.
Table 17: TextCensor Classes
|
Operator and Syntax
|
Matching Results
|
|
[LETTER]
|
Matches any single letter inside a word.
|
|
[DIGIT]
|
Matches any single digit inside a word.
For example, A[LETTER]B[DIGIT]C would match both “axb0c” and “aab9c”.
|
|
[NUM]
|
Use in place of a word to match any number made up of one or more digits. This class does not match numbers with a decimal point, or Asian language numbers that use words between characters
|
|
[CCARD]
|
Use in place of a word to match a series of digits that look like credit/payment card numbers. These numbers consist of up to 5 groups of digits, are up to 19 digits in length, and must pass checksum validation (using the Luhn algorithm). This class should match most card numbers.
|
|
[US-SSN]
|
Use in place of a word to match series of digits that look like US Social Security Numbers. Valid numbers must follow a specific format. However, the format is loosely defined and it is not possible to prevent accidental matching of other numbers.
|
|
[CAN-SIN]
|
Use in place of a word to match a series of digits that looks like a Canadian Social Insurance Number. Valid numbers must follow a specific format and pass a Luhn check.
|
7.4.2.9 Named Statements
You can give a TextCensor statement a name. When a named statement is executed, the result is stored. You can reference it in later statements within the same script.
If a statement contains only words or only uses positional operators, the stored result is the set of word positions found by that statement. If the statement uses any other operators then the result is logical.
You can reference the result of a statement by using [@name] inside a statement. This can be used anywhere that you would otherwise use the bracketed result of an operator.
|
|
Note: Naming a statement does not affect the statement’s score. To use a named statement as a macro expression, in most cases you should set the statement’s score to zero.
When using named statements within other expressions, remember that the result must match the required parameter type. If a statement returns a logical result you cannot use it as a parameter to a positional operator. Test your scripts before applying them in production.
|
7.4.3 Scoring a TextCensor Script
Each script is given a trigger threshold, expressed as a number. Each expression in a script is given a positive or negative score. If the total score of the content being checked reaches or exceeds the trigger threshold, the script is triggered.
The total score is determined by summing the scores resulting from evaluation of the individual expressions in the script.
For each expression, if the result is a true logical value, the expression score is the base score.
If the expression result is a position set (the word or phrase was found one or more times in the text), by default the final score of the expression is the base score. You can choose how to add the score when the expression is matched more than once. The options are:
Table 18: Cumulative scoring options
|
Option
|
Description
|
|
Every time
|
Each match of the words or phrases adds the score to the total.
|
|
First Match Only
|
Only the first match of the words or phrases adds the score to the total.
|
|
First N Matches
|
Each match, up to the number you set, adds the score to the total. For instance if the expression score is 5 and you select “first 3 matches,” then the expression can contribute up to 15 to the total score, but never more than 15.
|
Negative scores and trigger levels allow you to compensate for the number of times a word could be used in text that you do not want to match. For instance: if breast is given a positive score in an “offensive words” script, cancer could be assigned a negative score (since the presence of this word suggests the use of breast is medical/descriptive).
|
|
Note: Script evaluation always checks all expressions to obtain the final score. The order of expressions in a script is not significant. This is a change from earlier versions.
|
7.4.4 Creating Scripts
To work with TextCensor Scripts, in the left pane of the Management Console, select Policy Elements. Then select TextCensor Scripts from the right pane menu.
To add a TextCensor Script:
1.In the right pane of the Management Console, select TextCensor Scripts.
2.On the menu above the list, choose Add to open the TextCensor Script window.
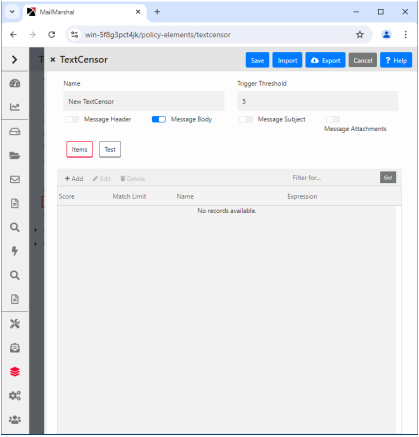
3.Enter a name for the script.
4.Select which portions of an email message you want this script to scan by selecting one or more of the check boxes Subject, Headers, Body, and Attachments
|
|
Note: The script will check each part separately.
For instance, if you select both Headers and Message Body, the script will be evaluated once for the headers, then again for the body. Script scoring is not cumulative over the parts.
|
5.Add one or more TextCensor items. To begin adding items, in the TextCensor Script window click New to open the Add TextCensor expression window.
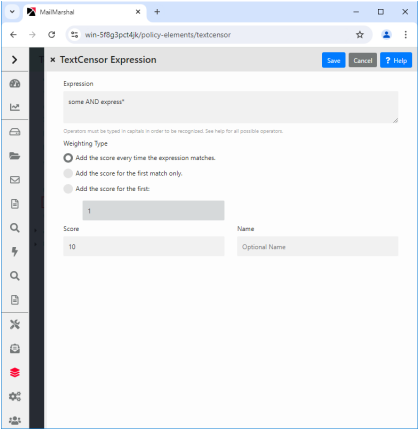
6.Enter the expression, optionally using the operators described earlier. For example:
(Dog FOLLOWEDBY hous*) AND NOT cat
In this example the expression score is added to the script total if the document contains the words dog house (or dog houses, and so forth) in order, and does not contain the word cat.
|
|
Note: TextCensor expressions are not case sensitive by default. However, quoted content is case sensitive. So textcensor would match TextCensor, but “textcensor” would not.
|
7.Select a score and contribution method for this expression (see “Scoring a TextCensor Script” for more information).
8.Click Add (or press Enter) to add the expression to this script. The window remains open so you can create additional expressions.
9.When you have finished entering expressions, click Close to return to the New TextCensor Script window.
10.Select a trigger threshold. If the total score of the script reaches or exceeds this level, the script is triggered. The total score is determined by evaluation of all expressions in the script.
7.4.5 Editing Scripts
You can change the content of an existing script, including the individual items and overall properties.
To edit a TextCensor Script:
1.Double-click the script to be edited in the right pane.
2.Edit an item by double-clicking it.
3.Delete an item by selecting it, and then clicking Delete.
4.Change the contents of other fields such as the script name, parts of the message tested, and trigger threshold.
5.Click Save to accept changes or Cancel to revert to the stored script.
7.4.6 Duplicating Scripts
Duplicate a script if you want to use it as the basis for an additional script.
To duplicate a TextCensor Script:
1.Right-click the script name in the Management Console.
2.Choose Duplicate from the context menu.
3.After duplicating the script, make changes to the copy.
7.4.7 Importing Scripts
You can import scripts in files. Use this function to copy a script from another MailMarshal installation, or to restore a backup.
|
|
Note: Some older product versions used a different format for the exported scripts. The earlier version scripts will be upgraded to the new format automatically. Any problems with upgrading will be reported.
|
To import a TextCensor Script from an XML file:
1.On the Action menu, choose New TextCensor Script to open the TextCensor Script window.
2.Click Import.
3.Choose the file to import from, and click Open.
4.In the Edit TextCensor Script window, click Save.
7.4.8 Exporting Scripts
You can save scripts in files. Use this function to move a script between MailMarshal installations, or to edit a script in another application such as Microsoft Excel.
To export a TextCensor Script to an XML file:
1.Double-click the name of the script to be exported in the right pane to open the Edit TextCensor Script window.
2.Click Export.
3.Enter the name of the file to export to, and click Save.
4.In the Edit TextCensor Script window, click Save.
7.4.9 TextCensor Best Practices
To use TextCensor scripts effectively, you should understand how the TextCensor facility works and what it does.
MailMarshal applies TextCensor scripts to text portions of messages. Depending on the portions you select, a script can apply to message subject, message headers, message bodies, and attachment content. MailMarshal can generally apply TextCensor scripts to the text of Microsoft Office documents and Adobe PDF files, as well as to attached email messages and plain text files.
|
|
Note: When you apply complex scripts to large documents, the script evaluation can consume significant system resources and process slowly. Use the minimum number of statements and operators, and match the most specific text possible.
|
7.4.9.1 Constructing TextCensor Scripts
The key to creating good TextCensor scripts is to enter exact words and phrases that are not ambiguous. They must match the content to be blocked. Also, if certain words and phrases are more important, you should give those words and phrases a higher score. For instance, if your organizational Acceptable Use Policy lists specific terms that are unacceptable, you should give those terms a higher score to reflect the policy.
In creating TextCensor scripts, strike a balance between over-generality and over-specificity. For instance, suppose you are writing a script to check for sports-related messages. If you enter the words “score” and “college” alone your script will be ineffective because those words could appear in many messages. The script will probably trigger too often, potentially blocking general email content.
You could write a better script using the phrases “extreme sports”, “college sports” and “sports scores” as these phrases are sport specific. However, using only a few very specific terms can result in a script that does not trigger often enough.
You can strike a good balance using both very specific and more general terms. Again using the example of sports related content, you could give a low positive weighting to a phrase such as “college sports.” Within the same script you could give a higher weighting to the initials NBA and NFL, which are very sports specific.
7.4.9.2 Decreasing Unwanted Triggering
TextCensor scripts sometimes trigger on message content which is not obviously related to the content types they are intended to match.
To troubleshoot unwanted triggering:
1.Use the problem script in a rule which copies messages and their processing logs to a folder. You could call this folder “suspected sports messages”.
2.After using this rule for some time, check on the messages that have triggered the script. Review the message logs to determine exactly which words caused the script to trigger. See “Viewing Messages”.
3.Revise the script by changing the expression scores, expression contribution method, trigger threshold, or key words, so as to trigger only on the intended messages.
4.When you are satisfied, modify the rule so as to block messages that trigger the script. You could also choose to notify the sender and/or the intended recipient.
7.4.10 Testing Scripts
When you are working with a TextCensor script in the Management Console, you can test it against a file or pasted text.
To test a TextCensor Script:
1.On the New or Edit TextCensor Script window, click Test.
2.To test using a file, select Test script against file. Enter the name of a file containing the test text (or browse using the button provided).
3.To test using pasted text, select Test script against text. Type or paste the text to be tested in the field.
4.Click Test. MailMarshal will show the result of the test, including details of the items which triggered and their weights, in the Test Results pane.